|
Light-field imaging is appealing to the mobile devices market because of its capability for intuitive post-capture processing.
Acquiring LF data with high angular, spatial and temporal resolution poses significant challenges, especially with space constraints preventing bulky optics.
At the same time, stereo video capture, now available on many consumer devices, can be interpreted as a sparse LF-capture.
We explore the application of small baseline stereo videos for reconstructing high fidelity LF videos.
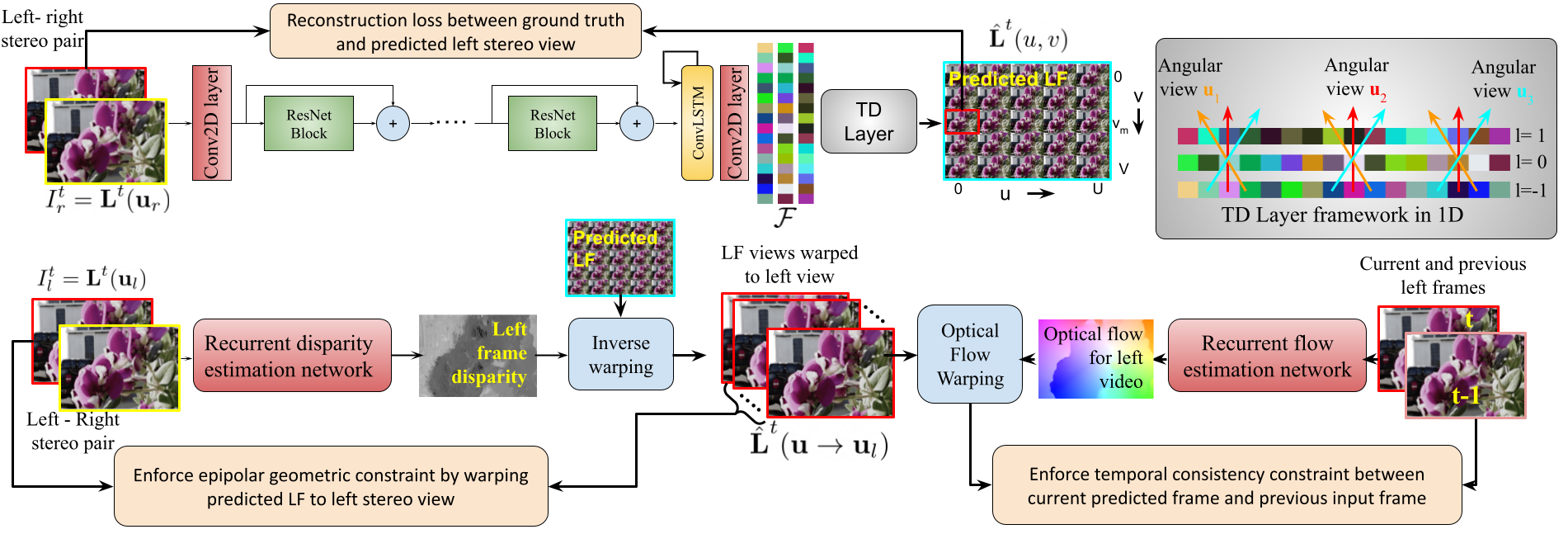
We propose a self-supervised learning-based algorithm for LF video reconstruction from stereo video.
The self-supervised LF video reconstruction is guided via the geometric information from the individual stereo pairs and the temporal information from the video sequence.
LF estimation is further regularized by a low-rank constraint based on layered LF displays.
The proposed self-supervised algorithm facilitates advantages such as post-training fine-tuning on test sequences and variable angular view interpolation and extrapolation.
Quantitatively the reconstructed LF videos show higher fidelity than previously proposed unsupervised approaches.% for LF reconstruction.
We demonstrate our results via LF videos generated from publicly available stereo videos acquired from commercially available stereoscopic cameras.
Finally, we demonstrate that our reconstructed LF videos allow applications such as post-capture focus control and region-of-interest (RoI) based focus tracking for videos.
|